

Redundant Design
A critical design consideration for enterprise networks is a layer of redundancy to protect against points of failure. This level of added redundancy begins at carrier selection and runs down to the aggregate distribution level. Route distribution between the border and core levels is done using the standard BGP/OSPF deployment practice. Configuration on the core level for the edge aggregate network is done using VRRP or HSRP. Further protection at the switch level can be achieved using the spanning tree protocol. Please see the Logical Diagram section for Altexxa Group's preferred network deployment map.
- Redundant by design from the carrier to the end switch
- Eliminating single points of failure to ensure uptime
- Utilizing industry standard deployment methods for redundancy
- Integrated security layer with border IDS filtering
Logical Diagram
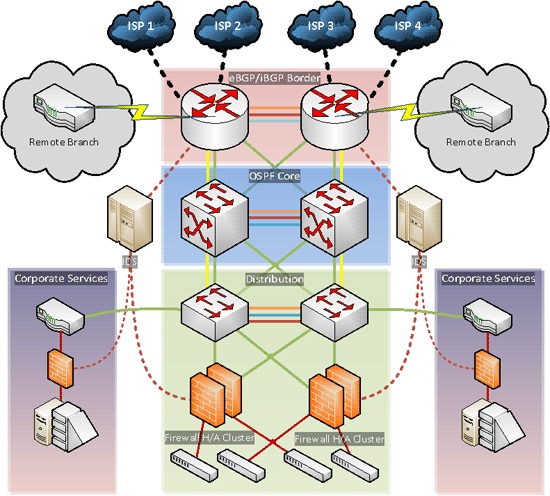
- Multiple route paths to eliminate points of failure
- Utilizing BGP and OSPF dynamic routing protocols
- Integrated security design with border IDS filter
Considerations
There are several considerations when designing and implementing fully redundant networks. Carrier selection should include diverse provider paths to reduce risk of geographical event impact. Border and core network devices require multiple connecting links for redundancy and scalability, so sufficient module expansion must be readily available for provisioning new links. Link aggregation (LACP) offers benefit for redundancy and future expansion. Hardware considerations must also be made depending on vendor and model selection to review other redundancy options (Cisco EtherChannel, Nexus vPC, etc) and compatibility with other protocols such as spanning tree.
- Diverse carrier selection to reduce impact from geographical risks
- Planning for future expansion via scalable design models
- Availability of supporting link aggregation implementations
- Vendor compatibility between redundancy protocols
Implementation
Adopting a high redundancy model during network implementation will include the use of modular devices with each critical component installed in pairs (supervisor module, line card, power supply). Device interconnectivity will include multiple physical links and utilizing link aggregation protocols within the device's logical configuration. Additional out-of-band management should be used on critical network devices.
Technical considerations such as selection of dynamic routing protocols for implementation would be determined based on equipment vendor. Other factors for implementation include transit bandwidth availability during failure or maintenance of a border device and opting for industry standard practices as opposed to proprietary configurations.
- Critical modules in each device to be installed in minimum pair configuration
- Out-of-band management for disaster recovery and risk mitigation
- Internal and external link availability during failure events